Key Cassandra Concepts
Apache Cassandra Datacenter
In Apache Cassandra (and respectively DataStax Enterprise products) a datacenter and rack do not directly correlate to a physical rack or datacenter.
An Apache Cassandra Datacenter is a group of nodes, related and configured within a cluster for replication purposes. Setting up a specific set of related nodes into a datacenter helps to reduce latency, prevent transactions from impact by other workloads, and related effects. The replication factor can also be setup to write to multiple datacenter, providing additional flexibility in architectural design and organization.
Apache Cassandra Racks
An Apache Cassandra Rack is a grouped set of servers. The architecture of Cassandra uses racks so that no replica is stored redundantly inside a singular rack, ensuring that replicas are spread around through different racks in case one rack goes down. Within a datacenter there could be multiple racks with multiple servers, as the hierarchy shown above would dictate.
To determine where data goes within a rack or sets of racks Apache Cassandra uses what is referred to as a snitch. A snitch determines which racks and datacenter a particular node belongs to, and by respect of that, determines where the replicas of data will end up.
Nodes and Virtual nodes
Snitch
Component of cassandra uses gossip protocol to learn about the the network, racks, data-center, IP, health etc.
- SimpleSnitch
- GossipingPropertyFileSnitch
- PropertyFileSnitch
- Ec2Snitch
Terminology

Keyspace
Analogous to a tablespace in Oracle.
Table
Partition
Rows
Strategies for creating keyspace
SimpleStrategy
create keyspace <keyspace_name> with replication = {'class':'SipleStrategy', 'replication_factor': 3}
NetworkTopologyStrategy
create keyspace <keyspace_name> with replication = {'class':'NetworkTopologyStrategy', 'DC1': 3, 'DC2': 1}
Consistency
Tunable Consistency - Write
Write request to the cluster may received to any of the node in the cluster called “Coordinator node” for that write request. Write will be success / fail based on the consistency value.
- ONE - At least one node acknowledged successful write.
- TWO - At least two node acknowledged successful write.
- THREE - At least three node acknowledged successful write.
- QUORUM - Majority of the node responsible for the data acknowledged successful write.
- ALL - All of the node responsible for the data acknowledged successful write.
- ANY - If write make it to the cluster (even to the coordinator node), it is considered as success.
Hinted Hand-off
The coordinator node try to write the data to all the node responsible for storing(based on number of replicas). But if one of the node is down on unresponsive, the data will be written to coordinator node and it will retry the writes till its success. In the mean time if the coordinator node goes down, the Hinted Hand-off fails which results in data inconsistency between node. this inconsistency will be repaied during read. (Read repair)
Tunable Consistency - Read
It determines how many nodes it will consult for the most current data before retiring the data.
- ONE - one node will be consulted.
- TWO - two one node will be consulted.
- THREE - three one node will be consulted.
- QUORUM - Majority of the node responsible for the data will be consulted.
- ALL - All of the node responsible for the data will be consulted.
- ANY -
Read Repair
In case of data inconsistency, one of the done may return incorrect digest. in that case, coordinator node read data from all the nodes and get the most recent data and write it back to the node with incorrect data.
It is advisable to use below command periodically to repair the inconsistency without waiting for the data to be read.
nodetool repair
Strong Consistency
(Write Consistency + Read Consistency) > Replication Factor
eg.
| Write Consistency | Read Consistency | Replication Factor | Strong Consistency |
|---|---|---|---|
| ONE | QUORUM | 3 | NO |
| ONE | ALL | 3 | YES |
| ONE | ONE | 3 | NO |
| QUORUM | QUORUM | 3 | YES |
Cassandra data types
- Numeric
| datatype | java equivalent |
|---|---|
| bigint | Long |
| decimal | BigDecimal |
| double | Double |
| float | Float |
| int | Integer |
| varint | BigInteger |
- String
| datatype | java equivalent | Description |
|---|---|---|
| ascii | String | US ASCII character string |
| text | String | UTF-8 character String |
| varchar | String | UTF-8 character String (Synonym to text) |
- Date
- timestamp - storing date and time
- timeuuid - Allows to store type 1 uuid which can be sorted based on date and time
- Other
- boolean
- uuid
- inet - for IP Addresses
- blob - for binary data
Counters
cqlsh:poc> create table rating(product_id varchar PRIMARY KEY, rating_counter counter);
cqlsh:poc> update rating set rating_counter = rating_counter+1 where product_id='abc-123';
cqlsh:poc> select * from rating;
product_id | rating_counter
------------+----------------
abc-123 | 1
(1 rows)
cqlsh:poc> update rating set rating_counter = rating_counter+1 where product_id='abc-123';
cqlsh:poc> select * from rating;
product_id | rating_counter
------------+----------------
abc-123 | 2
(1 rows)
Naming constraints for keyspace, tables, and columns
- no hyphen
- no spaces
- If starts with digit, surround with double quotes - “2015stats”
- Mixed case, surround with double quote. Else considered as Small - “firstName”
RULE OF THUMB - keep the name simple.
TTL
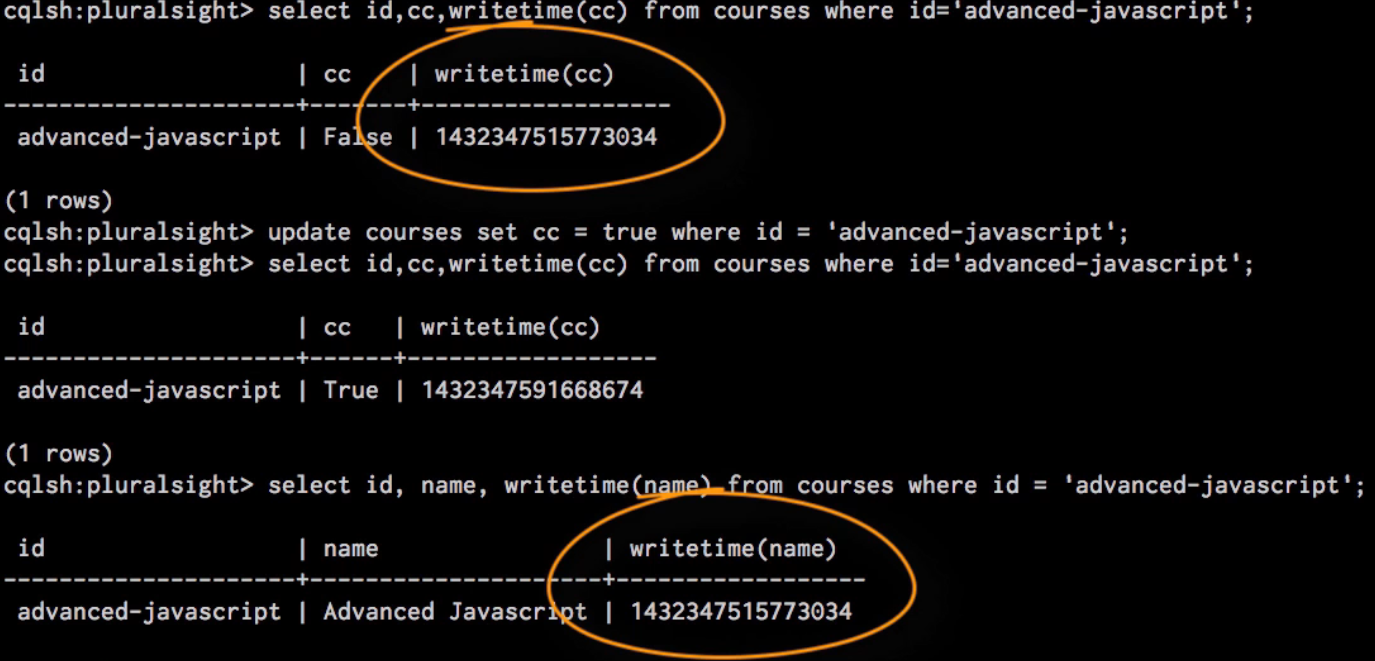
writetime function returns the write time of the data in a column. Write time is stored for every cell in the column.
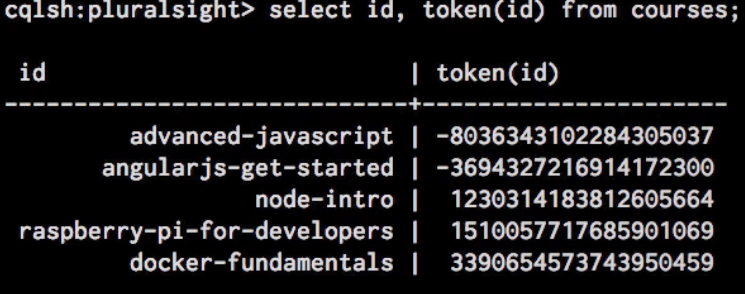
token function returns the token of the ID associated with the partition.